DEFENSE PRESENTATION
基于稳定扩散模型生成面部照片的方法研究
Research on Methods for Generating Facial Photographs Based on Stable Diffusion Models
答辩人:张庆双
指导老师:李焕哲
日期:2026.05.20
学校:河北地质大学
DEFENSE PRESENTATION
Research on Methods for Generating Facial Photographs Based on Stable Diffusion Models
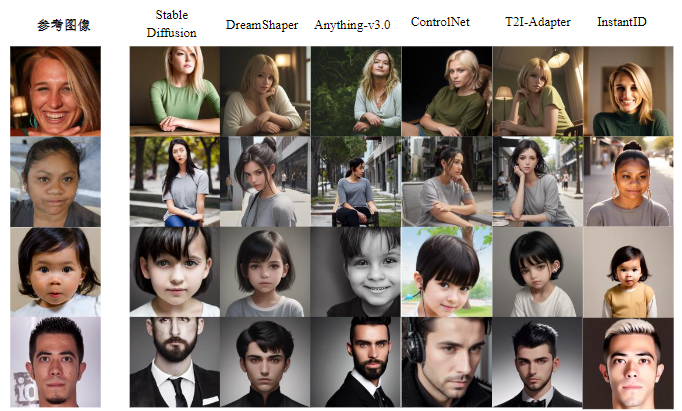
传统扩散模型在处理长文本描述时,难以精准捕捉深层语义,导致生成的图像与描述不匹配。文本提示在推理阶段易产生语义偏差,生成结果与输入条件不一致。
现有方法在处理多模态信息融合时,缺乏对边缘、法线等几何条件的精细化建模,图像结构完整性不足,生成图像在细节和结构一致性方面存在不足。
传统特征融合采用固定权重机制,无法动态适应复杂的语义结构(如修饰词-实体关系),难以根据不同区域自适应调整各模态信息的贡献。
GAN时代:DCGAN、Pix2Pix、CycleGAN等通过对抗训练提升视觉逼真度,但存在模式崩塌与训练不稳定问题。
扩散模型时代:DDPM、Stable Diffusion通过逐步去噪生成高质量图像,在质量与多样性上达成良好平衡,成为主流方法。
文本引导:自回归模型、GAN、扩散模型三类方法对比,扩散模型在质量与多样性上最优。
多模态引导:参考图像引导、语义布局控制、特征注入融合、空间结构约束四类方法各有优劣。
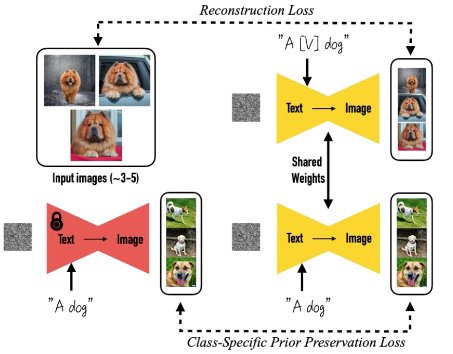
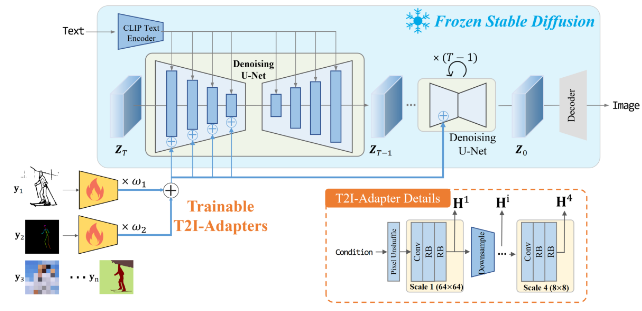
现有方法局限:参考图像引导依赖性强、多属性灵活性有限;语义布局方法对精细结构建模有限;特征注入方法空间约束能力有限;空间结构约束方法对条件质量敏感。→ 需要更有效的多模态融合与注意力优化机制。
扩散模型包含前向加噪和反向去噪两个过程,通过马尔可夫链框架逐步学习从噪声中恢复数据分布。
• 前向过程:逐步添加高斯噪声直至变为纯噪声
• 反向过程:学习去噪网络,逐步恢复原始数据
核心创新:在潜在空间而非像素空间执行扩散过程,大幅提升计算效率。
• VAE:编码器压缩图像,解码器还原结果
• U-Net:在潜在空间中进行噪声预测与去噪
• CLIP:将文本映射为条件嵌入引导生成
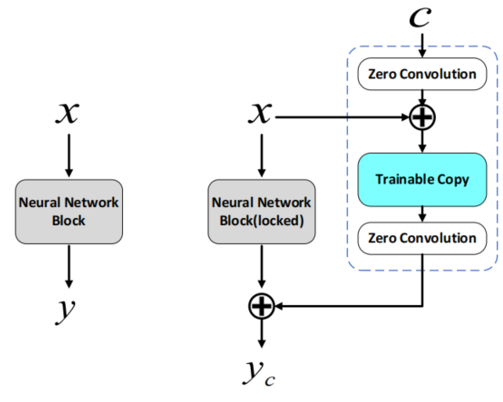
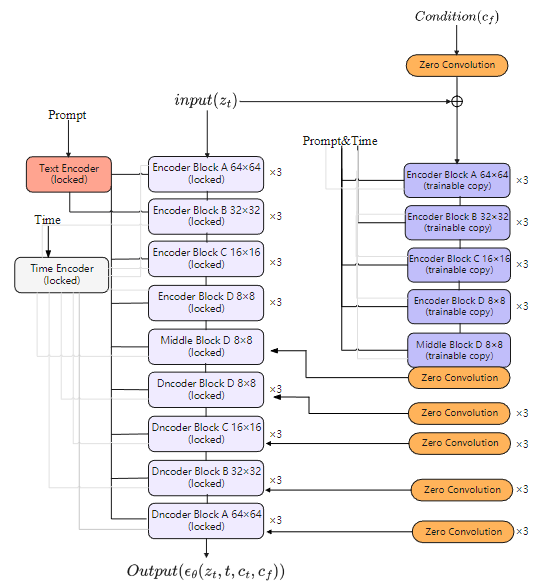
通过引入旁路控制网络实现精细化结构控制,冻结预训练参数的同时学习额外条件信号。
• 复制解码器结构构建并行辅助通路
• 零卷积:初始权重为零,逐步学习控制能力
保证训练初期不对主干模型产生干扰。
引入结构化语义先验,利用依存句法解析技术提取关键语义单元,将其映射至分层注意力策略中。通过解析提示词句法结构,对注意力权重进行动态重分配,实现关键语义区域的自适应增强。
融合边缘和法线辅助信息,构建轻量级门控机制自适应调整分支权重,增强结构控制力。基于ControlNet框架,引入边缘图与法线图作为互补的几何先验信息,实现对人脸2D轮廓与3D结构的联合建模。
基于语义先验与多分支融合,解决语义偏移问题,提升人脸关键特征区域的生成精度。空间自适应门控融合机制通过轻量网络生成多模态空间权重,根据不同区域自适应各模态信息的贡献。
BAM(Balance Attention Map)不改变扩散模型主体结构,作为外部调控机制嵌入到交叉注意力计算中,对语义信息的传递进行干预。
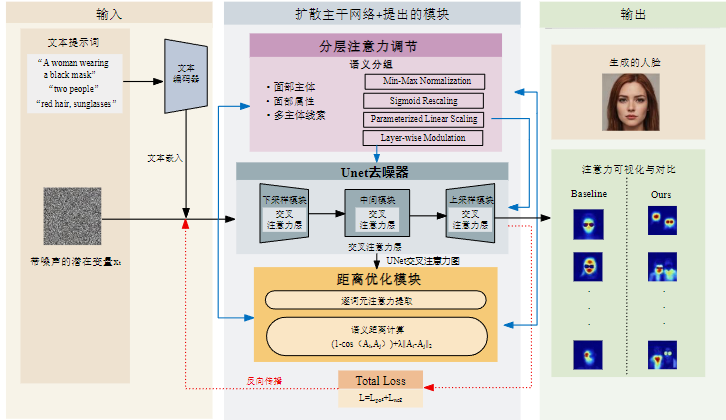
Min-Max归一化增强主体响应,抑制背景噪声
Sigmoid非线性映射强化属性与实体之间的语义绑定
线性缩放策略平衡多实体注意力分配
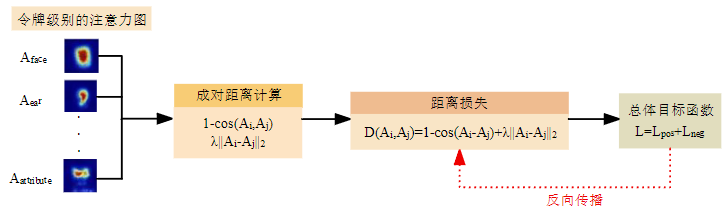
针对传统KL散度在面部生成中的局限性(倾向于拟合高概率区域,忽略低概率但关键的修饰语信息),BAM采用余弦相似度 + 欧氏距离的混合距离度量,同时实现方向与位置的对齐约束。
• 余弦相似度约束属性与实体特征的方向一致性
• L2距离控制特征尺度,防止语义偏移
• λ = 0.5 平衡方向与幅值两个层面的优化
正向损失 Lpos:最大化修饰语与对应实体名词注意力图的重叠度
负向损失 Lneg:增加修饰语-实体对与无关词汇的距离,抑制错误属性关联
| 数据集 | 规模 | 文本类型 | 构建方法 |
|---|---|---|---|
| CelebA-3k | 3000条 | 属性短语 | 基于CelebA图像+属性标签生成 |
| FFHQ-3k | 3000条 | 属性短语 | 基于FFHQ图像+BLIP描述生成 |
| FacePrompt-3k | 3000条 | 自然语句 | 大语言模型语义拓展+句式改造 |

| 数据集 | 模型 | IS (↑) | CLIP Score (↑) | TIFA (↑) |
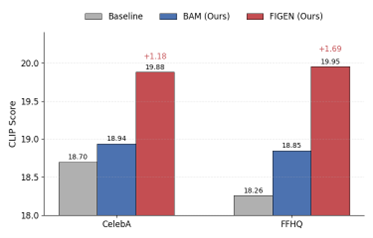
|---|---|---|---|---|
| CelebA-3k | BAM(ours) | 8.65 | 18.94 | 1.18 |
| SynGen | 8.53 | 18.53 | 1.17 | |
| A&E | 8.65 | 18.71 | 1.15 | |
| D&B | 8.68 | 18.34 | 1.17 | |
| FFHQ-3k | BAM(ours) | 12.61 | 18.85 | 1.16 |
| SynGen | 12.64 | 18.08 | 1.17 | |
| A&E | 11.56 | 18.26 | 1.13 | |
| D&B | 12.57 | 17.88 | 1.15 | |
| FacePrompt-3k | BAM(ours) | 9.34 | 19.36 | 1.18 |
| SynGen | 9.53 | 18.44 | 1.17 | |
| A&E | 9.20 | 18.25 | 1.13 | |
| D&B | 10.07 | 18.13 | 1.14 |
+2.21%
CelebA-3k 语义一致性提升
+4.26%
FFHQ-3k 语义一致性提升
+4.98%
FacePrompt-3k 语义一致性提升
BAML:仅使用分层注意力;BAMD:仅使用距离度量;BAM:完整模型
| 数据集 | 模型 | IS | CLIP Score | TIFA |
|---|---|---|---|---|
| CelebA-3k | BAML | 8.35 | 18.72 | 1.18 |
| BAMD | 8.23 | 18.69 | 1.17 | |
| BAM | 8.65 | 18.94 | 1.18 | |
| FFHQ-3k | BAML | 12.44 | 18.38 | 1.17 |
| BAMD | 11.62 | 17.49 | 1.16 | |
| BAM | 12.61 | 18.85 | 1.17 | |
| FacePrompt-3k | BAML | 9.95 | 18.34 | 1.15 |
| BAMD | 9.83 | 18.12 | 1.14 | |
| BAM | 9.34 | 19.36 | 1.18 |
结论:三种注意力策略协同效果优于单独使用;混合距离度量相比传统KL散度,在语义一致性指标上有显著提升。
通过引入 2D边缘 + 3D法线 的联合建模,增强模型对图像几何特征和细节纹理的保留能力:
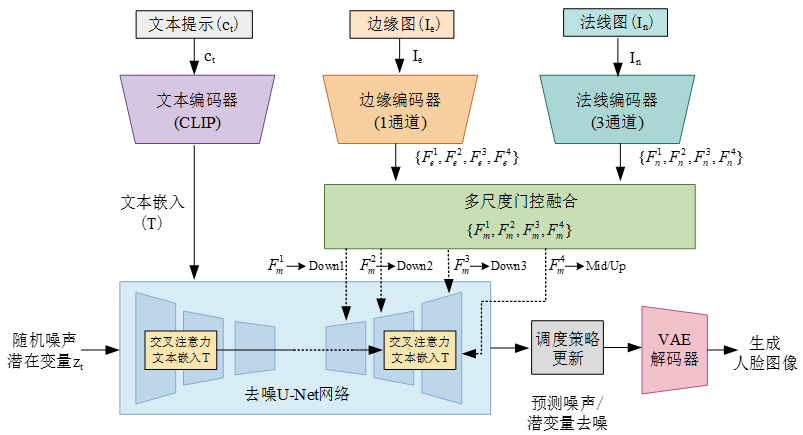
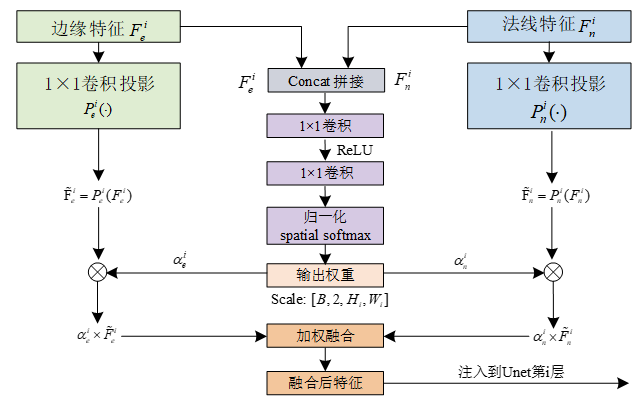
在第 i 个尺度上,边缘特征 Fei 与法线特征 Fni 经过拼接输入门控网络,生成空间自适应权重图 αei 和 αni,对投影后的双分支特征进行逐元素加权求和,得到融合特征 Fmi,并注入U-Net对应层级。
为防止某一模态长期主导,训练阶段引入权重熵正则项,对门控权重分布加以约束,确保边缘与法线模态均能有效参与优化。
• Ldiff:标准噪声预测均方误差损失
• Lreg:门控权重熵正则损失,鼓励均衡的模态分配
• λreg:正则项权重系数,平衡重建目标与门控约束
| 环境 | 名称 | 配置 |
|---|---|---|
| 硬件 | GPU | NVIDIA RTX 3090 |
| CUDA | 12.4 | |
| 软件 | Python | 3.8.5 |
| PyTorch | 1.12.1 | |
| Diffusers | 0.19.0 | |
| Transformers | 4.30.2 |
• 图像分辨率:512 × 512
• 优化器:AdamW,学习率 1e-5,权重衰减 1e-2
• 批大小:8,训练 100 epoch
• 训练周期:约 5天(RTX 3090)
• 单张推理时间:24.2秒
• 参数量增量:仅 +2%(vs 单条件ControlNet)
• 推理延迟增量:< 5%
• DDIM采样 50步,CFG = 7.5
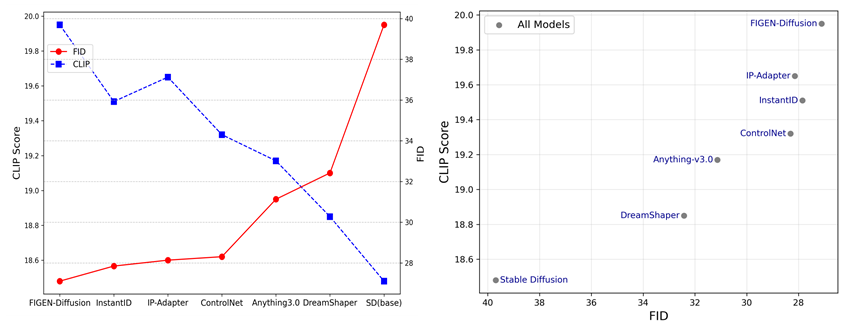
| 模型 | FID↓ | IS↑ | CLIP↑ | PSNR↑ | SSIM↑ |
|---|---|---|---|---|---|
| Stable Diffusion | 42.16 | 8.12 | 18.35 | 17.82 | 0.495 |
| DreamShaper | 34.57 | 8.75 | 18.72 | 18.65 | 0.521 |
| Anything-v3.0 | 33.23 | 9.02 | 18.95 | 19.10 | 0.536 |
| ControlNet | 29.82 | 9.68 | 19.15 | 19.75 | 0.552 |
| T2I-Adapter | 29.55 | 9.85 | 19.42 | 20.15 | 0.568 |
| InstantID | 28.91 | 10.05 | 19.31 | 21.45 | 0.612 |
| FIGEN (Ours) | 27.85 | 10.12 | 19.88 | 21.80 | 0.628 |
CLIP Score较T2I-Adapter提升 +2.37%
| 模型 | FID↓ | IS↑ | CLIP↑ | PSNR↑ | SSIM↑ |
|---|---|---|---|---|---|
| Stable Diffusion | 39.69 | 8.35 | 18.48 | 18.05 | 0.501 |
| DreamShaper | 32.42 | 8.92 | 18.85 | 18.87 | 0.527 |
| Anything-v3.0 | 31.13 | 9.15 | 19.17 | 19.33 | 0.543 |
| ControlNet | 28.31 | 9.78 | 19.32 | 20.15 | 0.561 |
| T2I-Adapter | 28.14 | 9.95 | 19.65 | 20.55 | 0.573 |
| InstantID | 27.85 | 10.20 | 19.51 | 21.80 | 0.625 |
| FIGEN (Ours) | 27.11 | 10.28 | 19.95 | 22.15 | 0.638 |
CLIP Score较T2I-Adapter提升 +1.53%
不同数据规模下 FID 评估结果
FID随数据规模增加持续下降,模型具备良好的分布学习能力
各模型 CLIP Score 对比(CelebA & FFHQ)
| 模型 | Edge | Normal | FID↓ | IS↑ | CLIP↑ | SSIM↑ |
|---|---|---|---|---|---|---|
| Baseline | ✕ | ✕ | 29.81 | 9.68 | 19.15 | 0.552 |
| Edge only | ✓ | ✕ | 28.65 | 9.82 | 19.36 | 0.581 |
| Normal only | ✕ | ✓ | 28.40 | 9.75 | 19.48 | 0.596 |
| FIGEN | ✓ | ✓ | 27.85 | 10.12 | 19.88 | 0.628 |
| 模型 | Edge | Normal | FID↓ | IS↑ | CLIP↑ | SSIM↑ |
|---|---|---|---|---|---|---|
| Baseline | ✕ | ✕ | 28.32 | 9.78 | 19.32 | 0.561 |
| Edge only | ✓ | ✕ | 27.67 | 9.92 | 19.55 | 0.586 |
| Normal only | ✕ | ✓ | 27.35 | 9.88 | 19.62 | 0.603 |
| FIGEN | ✓ | ✓ | 27.13 | 10.28 | 19.95 | 0.638 |
边缘图:有效约束人脸整体结构轮廓,提升空间一致性与结构清晰度,但对语义对齐增强有限
法线图:刻画面部细节、光照变化及几何表面特性更强,PSNR/SSIM提升更显著
两者结合:边缘提供全局结构引导,法线增强局部几何细节,协同作用在所有指标上取得最优 → 验证了多模态条件融合策略的有效性
五官边缘区域轻微模糊或纹理不连续(高频细节建模有提升空间)| 复杂语义与多条件叠加时属性表达存在耦合现象 | 光照条件变化大时亮度分布与阴影关系不够严格

将BAM和FIGEN-Diffusion两种算法有效集成,开发面向个性化人脸生成的系统,按照模块化理念设计,保障可扩展性和高效性。
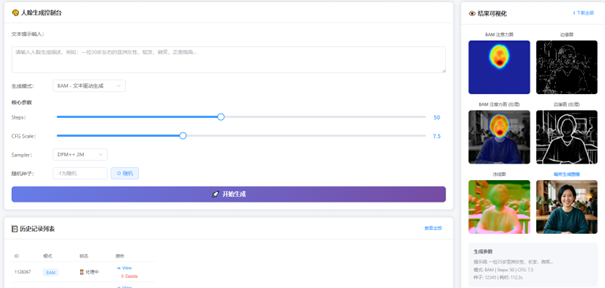
| 模式 | 分辨率 | 推理时延 | 显存占用 |
|---|---|---|---|
| 文本驱动生成 | 512×512 | ~106.8s | ~9.6GB |
| 条件控制生成 | 512×512 | ~138.9s | ~11.2GB |
• 5并发用户可稳定响应
• 10并发用户通过异步队列调度维持服务可用
• 安全测试:权限隔离、SQL注入防护、文件上传限制、接口流量控制均通过
(1)BAM模块:在CelebA-3k和FFHQ-3k上语义一致性分别提升2.21%和4.26%,FacePrompt-3k提升4.98%
(2)FIGEN-Diffusion:融合边缘与法线多模态条件,CLIP Score分别提升2.37%和1.53%
(3)轻量级门控机制:仅+2%参数量、<5%推理延迟,实现空间位置感知的自适应权重调节
(1)大角度姿态变化时边缘和法线融合可能出现特征错位
(2)复杂语义叠加下属性解耦不彻底,局部五官边缘偶发轻微模糊
(3)光照条件变化较大时亮度分布不够严格
(4)主要针对人脸任务,通用复杂场景泛化能力待验证
(1)搭建多模态条件融合的弱耦合体系,增强复杂条件适应能力
(2)引入强化学习奖励策略,动态调整生成关注范围
(3)纳入物理渲染损失函数与对抗训练,提升光照真实感
(4)推广至通用图像生成任务,提升跨领域实用性
意见(1)
建议在第三章、第四章加入对比表,明确说明新增工作点和已有工作的不同之处。
→ 修改:新增表3.5和表4.6,明确自身方法与已有方法的差异。
意见(2)
建议补充说明参考图像来源、是否逐样本配对、结构条件图来源,以及为何可使用像素级指标。
→ 修改:在4.3.3评估指标部分新增PSNR和SSIM适用性说明。
意见(3)
论文对比方法在训练数据、模型规模、是否微调、输入条件和身份约束机制不完全一致,建议补充统一实验设置。
→ 修改:在4.3实验设置部分补充了统一实验条件细节。
意见(4)
第5章系统测试缺少量化指标,建议增加推理时间、吞吐量、显存占用、失败率、队列等待时间、移动端响应时间及BAM/FIGEN性能对比。
→ 修改:第五章5.4新增性能量化对比表,完善测试指标。
意见(1)
表4.2显示本文方法均取得最优,但实验分析部分缺少理论分析,也未说明在何种条件下本文方法存在短板。
→ 修改:在4.3实验细节的定量分析部分新增理论分析与方法局限性分析。
意见(2)
建议增加第三章和第四章方法的时间复杂度分析。
→ 修改:在实验细节的定量分析部分新增时间复杂度分析。
感谢导师李焕哲、胡吉朝和秦彭老师的悉心指导与帮助。
感谢实验室同门的陪伴与支持。
感谢家人和挚友的鼓励与关爱。
感恩之心,藏于心底;致谢之意,见于言辞。
—— 张庆双,河北地质大学,2026年5月